Completed a Udemy course – “Leadership: Practical Leadership Skills” URL: https://www.udemy.com/certificate/UC-d548fafd-6928-4fe4-959b-3d01493a0c34
-
-
Thanks Capgemini! 🏆 Delighted to have secured 3rd place in the AI Activate Prompt Battle. Two rounds down, with more to come! Since joining Capgemini, I’ve been amazed by the number of learning opportunities available to employees. It’s always exciting to learn new things and put that knowledge to the test through different challenges and competitions.
-
Step 1 – Get an NVIDIA API Key from build.nvidia.com a. You will require a NVIDIA cloud account to be created and verified in order to generate an API key.b. Browse the ‘Models’ and choose one. I will go with GLM-5.2 which is what first came up when I sorted using ‘recent’ filter. Good part is, there is no credit card requirement, and most models (non-enterprise) are free for your learning and developing. It is worth noting down that the unlike other providers who use token consumption based billing, NVIDIA is different here. You can find the ‘Generate API Key’…
-
Thanks Efekta Education and Capgemini for providing a platform to improve language skills, especially through AI-powered methods. Looking forward to the next level soon!
-
-
-
Keeping this here just for future reference
-
Yesterday 28 June 2026, I had the honor of speaking at the YMCA National Planning Forum in Alwaye, Kerala. We tackled a big topic: how Artificial Intelligence fits into a historic service organization. I kept the tech jargon out of it. We focused purely on how AI can serve as a practical everyday assistant for YMCA Secretaries and staff. Think about the hours spent drafting funding proposals, writing reports, or organizing data. When AI takes over those repetitive tasks, it gives our teams something invaluable. It gives them time. That means more time for what actually matters. More time for…
-

Items used: Connector mapping: ESP32 MAX7219 VIN VCC GND GND D23 DIN D18 CS D19 CLK platformio.ini: main.cpp:
-
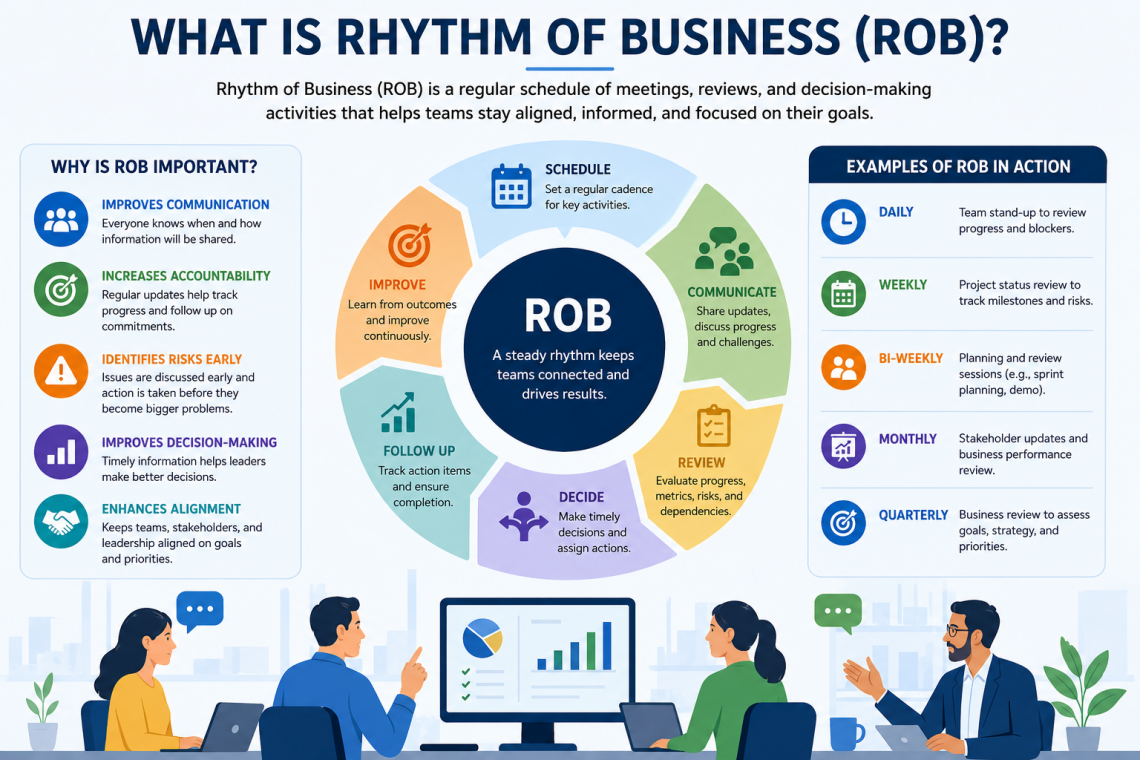
Every successful project or business depends on good planning, regular communication, and timely decisions. Whether it is developing a software application, launching a new product, or managing day-to-day business operations, teams need a structured way to stay aligned. This is where Rhythm of Business aka ROB comes into the picture. Rhythm of Business is a regular schedule of meetings, reviews, and decision-making activities that helps teams work together effectively. Instead of conducting meetings only when problems arise, organizations follow a planned routine to review progress, discuss challenges, and make decisions. Note that, ROB is commonly used in enterprise project and…