-
-
Keeping this here just for future reference
-
Yesterday 28 June 2026, I had the honor of speaking at the YMCA National Planning Forum in Alwaye, Kerala. We tackled a big topic: how Artificial Intelligence fits into a historic service organization. I kept the tech jargon out of it. We focused purely on how AI can serve as a practical everyday assistant for YMCA Secretaries and staff. Think about the hours spent drafting funding proposals, writing reports, or organizing data. When AI takes over those repetitive tasks, it gives our teams something invaluable. It gives them time. That means more time for what actually matters. More time for…
-

Items used: Connector mapping: ESP32 MAX7219 VIN VCC GND GND D23 DIN D18 CS D19 CLK platformio.ini: main.cpp:
-
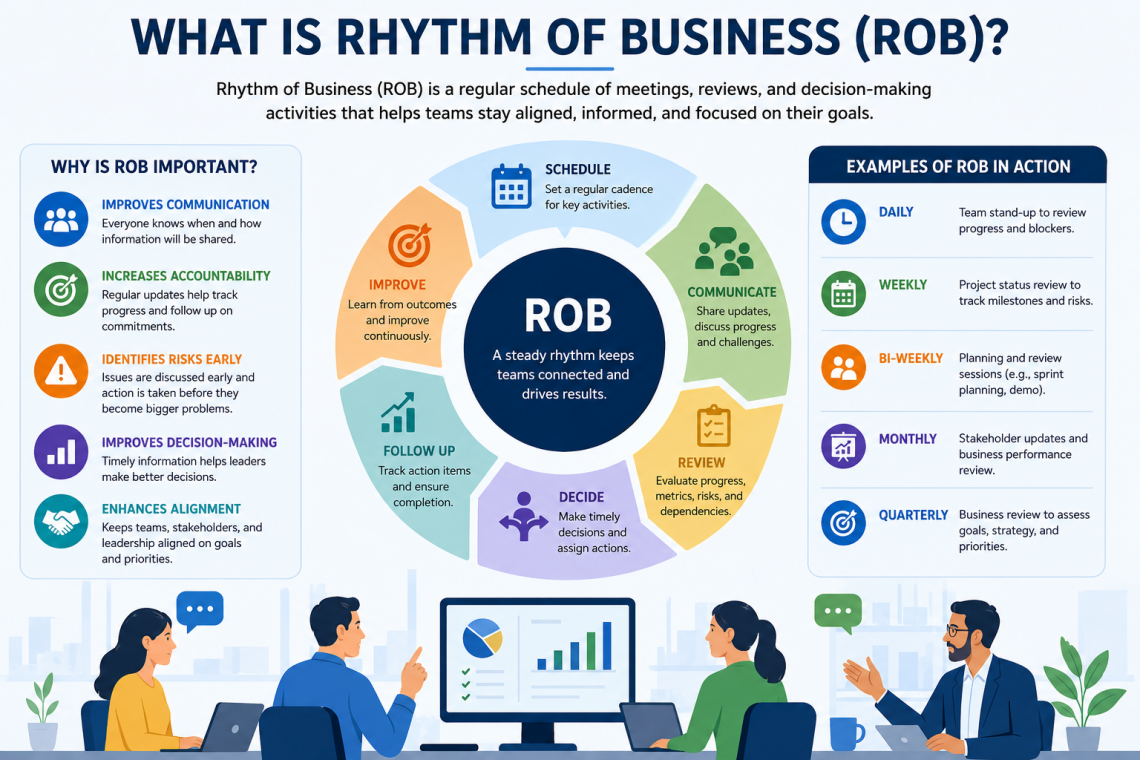
Every successful project or business depends on good planning, regular communication, and timely decisions. Whether it is developing a software application, launching a new product, or managing day-to-day business operations, teams need a structured way to stay aligned. This is where Rhythm of Business aka ROB comes into the picture. Rhythm of Business is a regular schedule of meetings, reviews, and decision-making activities that helps teams work together effectively. Instead of conducting meetings only when problems arise, organizations follow a planned routine to review progress, discuss challenges, and make decisions. Note that, ROB is commonly used in enterprise project and…
-
My thoughts on how Fable might be disrupting how other models ‘think’ Every new frontier model promises better benchmarks, larger context windows, and improved reasoning. While these capabilities matter, they often distract from the more important question for architects: How does this change the way we build AI systems? Read full article here – Architecting for Frontier Models: Lessons from Claude Fable 5 | LinkedIn
-

Years ago, one of my mentor gave me a piece of advice that sounded oddly simplistic at the time: “Give ’em the bones, and they’ll play with it.” I laughed when I first heard it. Back then, I interpreted it as a shortcut mindset. A way of saying “just throw something out there” Over the years, working across enterprise programs, modernization initiatives, and high pressure delivery environments, I realized it meant something far more practical. It was never about lowering standards. It was about understanding how organizations react to uncertainty. As architects, we operate in an uncomfortable middle layer: The…
-

Every few years, most of us get handed the same assignment in a new disguise. The words change, but the shape is always familiar: “We need you to join this project. It is already running. The previous person just left. Can you get up to speed quickly and take ownership?” It does not matter whether you are an architect, a developer, a tester, a database administrator, a DevOps engineer, a support executive, a business analyst, a product owner, or a project manager. The assignment is the same. Jump onto a moving train, learn the route, befriend the passengers, and eventually…
-

Token estimation is not a solved problem, but it is a much more manageable problem than most teams realize. This article breaks down the practical strategies for projecting token usage before your prompts ever reach the model. Read my new AI Architecture article here – https://www.linkedin.com/pulse/token-budgeting-predicting-llm-costs-before-you-hit-send-praveen-nair-ovo0c
-
Happy to share the news that I am a Microsoft Certified AI Transformation Leader now